Features I Wish Firebase Had

Firebase is a service I use every day and love. Ever since I started using it back in 2019, I’ve fallen in love with it. Since then, I have used Firebase in numerous projects of mine and many projects for the companies I have worked at.
I’ve used it in projects that had a part of Firebase’s offerings integrated, for example, user authentication with Firebase Auth or Push Notifications with Firebase Cloud Messaging, and also in projects where I’ve gone all-in with Firebase’s offerings. That is, database with Firestore, User Authentication with Firebase Auth, Backend Functions with Firebase Cloud Functions, push notifications with Cloud Messaging and the entire suite of features they offer.
The main selling point of Firebase is primarily its:
- Ease of use and integration.
- Completely Managed Services.
- Range of Integratable Services.
For example, if you want to get users to be able to login with email and password on your app, instead of having to write a backend for it to do so. You can simply use their managed service Firebase Auth, integrating it into your app is a single file to setup everything including sign-in, password reset, email verification. That’s not it, it has OTP Sign In and all other Social Logins you could think of.
await auth().signInWithEmailAndPassword(email, password);
await auth().currentUser.sendEmailVerification();
await auth().sendPasswordResetEmail(email);

As for the integration part, they do a fantastic job. You can use your Firebase Auth Credentials to sign in users that can have granular and well-defined access to your Firestore or Realtime Database, similarly for Cloud Storage. You can access any one of Firebase’s offerings from any of the other offerings from Firebase.
There have been times where all of Firebase’s initial setup with my app has taken less than an hour.
So you might be thinking, “Okay smart guy! If you’re so happy with Firebase and love it this much, then what is this blog post about?”
It’s true that I love Firebase, as I have specified numerous times above. However, I do feel it has shortfalls at certain places. And that’s what I am going to discuss in this article. I hope this article reaches the Firebase team, I appreciate the effort they constantly put in to make Firebase a great service that is so difficult to move away from.
1. Better Querying Capabilities in Firestore
Firestore is great at basic data modelling choices, it’s NoSQL and can scale infinitely in the cloud, it’s great when you simply want to spin up a database and start playing around with it while your app grows.
Sooner or later however you will eventually realize that a few very basic features that are present in almost every other database system are missing.
A few months ago I would have said that it is the absence of the != (Not Equal To) operation that makes or breaks the deal. But good news, Firestore now supports not-equals operations in their latest SDKs.
The basic querying feature that remains now is an or operation between two different fields in Firestore. For example, if I want to fetch the list of users from the users collection that have an email address equal to abc@xyz.com or a phone number equal to 1234567890, I can’t do that.
// You can only do AND, not OR.
firestore()
.collection("users")
.where("email", "==", "abc@xyz.com")
.or() // How awesome would it be if this was a chainable query function?
.where("phone", "==", "1234567890");
Another query feature that seems to be missing from Firestore is string-based search.
For example, if I want to fetch all users from the users collection that have John in their name. With Firestore I can’t do that.
firestore()
.collection("users")
.where("name", "contains", "John"); // Won't work.
Another string querying capability that would be great is case-insensitive comparison of strings, but string querying comes first.
It’s these small things that lead to the need for intervention of other workarounds or techniques or worse yet the need for switching databases completely.
I know some of the people that have worked with indexes in NoSQL databases before or people who have an idea about how Firestore works in the background will probably say that it’s because of the indexes that Firestore has to maintain to keep every query fast, which is correct, there is an infinite level of complication that I as a consumer will probably never get to fully understand.
But even the != feature was previously thought and even told by the Firestore team to be difficult to accomplish, but their talented team did it anyway. So I am hopeful for the above features to be implemented as Firestore evolves as a database.
2. Better Pagination in Firestore
I have been there, implementing pagination for my data in Firestore, the inbuilt query cursors work fine for some normal use cases, but I am not always a fan of infinite scroll which their query cursors move towards, sometimes it’s required to show users the page number and number of documents.
The number of documents in a collection can be aggregated using different solutions like Cloud Functions on the backend, or increment operations on the frontend (I prefer the frontend approach with transactional increment and appropriate security rules). But again, this is a workaround, not like a collection.countDocuments() feature that we get with services like MongoDB or count(*) operation with SQL Documents. It would be great to have it.
One easy workaround I couldn’t find though is the direct navigation to document 25 matching a resultset. As the query cursors doc explain above, the startAfter or startAt methods in Firestore work with document references, numeric values and string values in some cases, but there is no native offset option on the frontend SDK, and even if it is on the Firebase Admin SDK, if you use an offset value of 50, it charges you for the 50 reads it needed to get to that offset. So even if I show people a list of pages, I can’t get them to skip directly to page 5 of 10.
firestore()
.collection("posts")
.where("isDraft", "==", false)
.offset(15); // Hopefully one day this won't result in 15 extra charged reads and is available on the frontend SDK.
This feature would actually be one of the best additions to the Firestore power set and is my personal favourite out of all the possible additions I list here.
3. User Creation Limited to Console/Admin in Firebase Auth
I have had many apps where I want only a select list of users to have access. Now Firebase Auth is a great solution for apps where you just want to plug and play and want any person to sign up for apps. But not so much for apps that want a guarded user base.
Now anyone might think: “Well just don’t have the signup process on your app.” That might sound great initially unless you realize that the Firebase app’s credentials are supposed to be public and are usually very easy to find out from the sources of your app, especially if its a web app.
Any halfway decent hacker or just someone on the lookout for something fishy will be able to simply use the browser console, initiate the firebase instance and create a user with an email and password. If the database’s security rules are simply set to allow access to signed-in apps, which I have seen most insecure apps do, the person now has access to an account they can sign in with.
There are workarounds, of course, some involve locking access to database users, some include deleting new users from cloud functions, but there isn’t a native way to simply disable new user signups or simply limit the creation of users from the Firebase Console or the Admin SDK. It would be extremely helpful if there was.
4. DDOS Attack Detection in Cloud Functions
Cloud Functions are great, I use them everywhere, in almost all projects where I have been lazy to create my own backend and have to worry about scaling them. Cloud Functions provide enough free invocations on both the Spark and Blaze plan that you probably only need to worry about Network Egress costs and not the actual invocations until your application is very-very large and popular.
But once the application does get popular, there is a possibility that someone somewhere would be very interested in disrupting your services. In most cases, attackers will try running a Distributed Denial Of Service or DDOS attack on the infrastructure in which they get millions of computers to quickly send thousands or hundreds of thousands of requests to the infrastructure to take it down completely, leading to normal users not being able to access services.

In our case, they won’t be able to take down the infrastructure because Google has got our backs with a planetary-scale infrastructure capable of handling massive loads and attacks. But what you’ll notice is that since the infrastructure wouldn’t go down, those function invocations to your Cloud Functions will be billed even though they might have been a part of a deliberate DDOS Attack.
The tricky part here is proving that spike was a DDOS Attack because DDOS Attacks are very tricky to detect, what if the request spike was not a DDOS Attack but a sign that your application was somewhere published in the news and suddenly got famous enough for thousands of users to flock to your app. So more often than not, if there were 8 million invocations over the 2 million free function invocations, you would have to pay for that.
You can always guard the actions you perform inside your function behind an authorization wall and send back an error if there isn’t authorization present, but for that to happen, the function needs to be invoked first which is a bummer. A better solution is to specify the max number of instances that a cloud function can be associated with if you know the amount of traffic you can get, but then again if you know the amount of traffic you get, then that beats the point of Serverless Computing where you deploy something and don’t have to worry about it again.
It will be interesting to see how businesses deal with this and how they cope with DDOS Attacks on their Cloud Functions and what resolution Google has for them.
5. More Transparent Cloud Functions Build and Storage Process
When I upgraded from a Node.js 8 to Node.js 10 runtime as suggested by Firebase, I didn’t expect to get the shock of a lifetime. When I upgraded to the blaze pay as you go plan from Firebase, the process was pretty smooth, and so did I think it would be for upgrading functions to Node.js 10.
When I run firebase deploy --only functions on my local repo, and rested my spine back seeing the update processes work, the process was successful in around 2 minutes, after that I went back to my functions code, wrote some more functions and deployed the whole thing around 4-5 times due to multiple changes I had made. Those deployments finished and I went back to bed.
Next morning I wake up, and head to my Firebase console, I see my cloud storage bucket usage having ballooned to around 3.2GB from 75MB, I started sweating about where the extra usage came from, it was pretty scary to think of factors such as a security breach where external users might have gotten access to my storage buckets or my application might have suddenly hit a huge userbase.
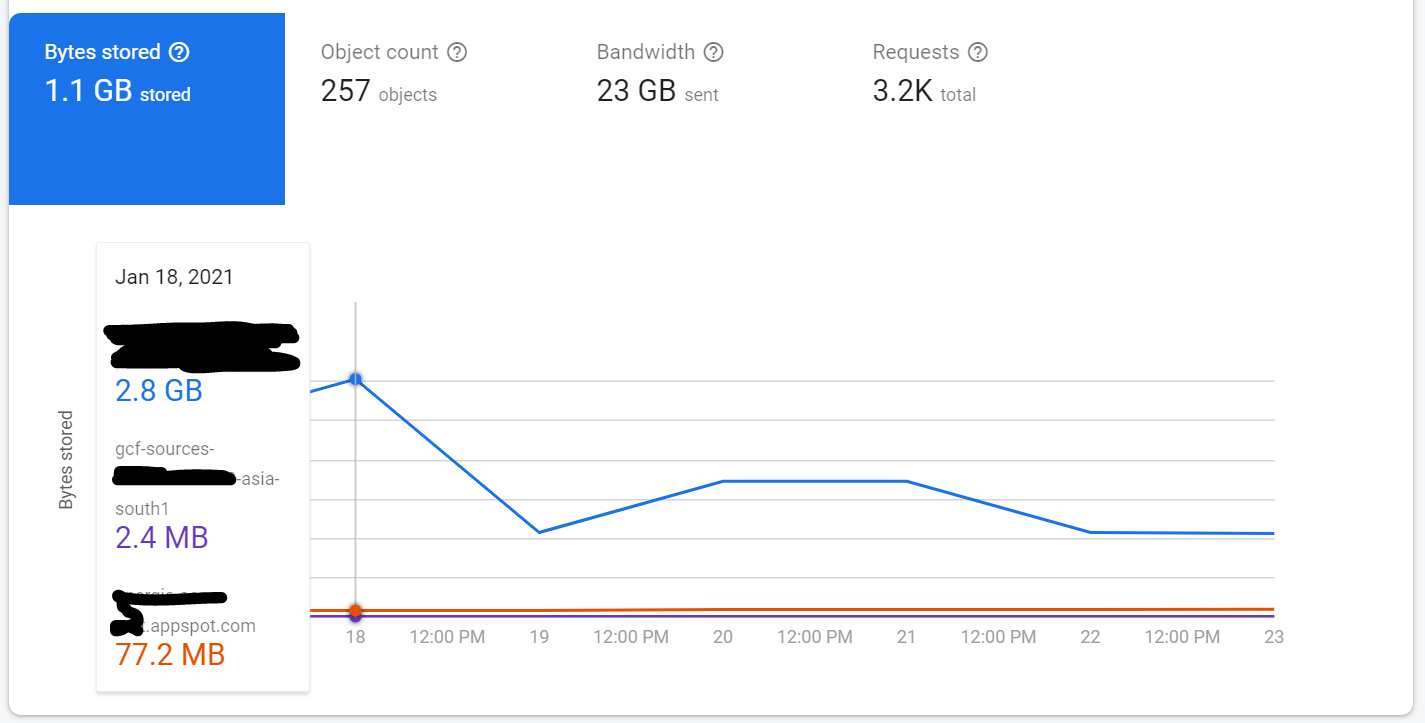
After a few minutes of searching, I find out that there were new buckets created automatically to build container images for my Node.js 10 functions. I later realized Firebase Cloud Functions use Google Cloud Build to containerize their functions which in turn uses the Cloud Storage Buckets with Artifact Registry in order to store build artifacts (If you don’t understand it, don’t worry, neither do I), and the storage, bandwidth for all those functions has to be paid for by the user.
At that moment, I wasn’t exactly a cloud expert and hence didn’t understand the reasons behind this and that’s what brings me to this point, Firebase should transparently tell the processes behind these systems in an easy to understand way because if the people using Firebase are expected to understand a lot of these quirks that come with using these services, we would simply use Google Cloud instead of the abstracted Firebase offerings.
For example, the files that accounted for 98% of the 3.2GB are actually ‘artifacts’ and can be deleted from time to time, you can do it manually by going to ‘Cloud Storage’ from Google Cloud Console (Every Firebase project is also a Google Cloud Project) and removing all files from the ‘artifacts’ bucket or you can even set up lifecycle policies to auto-delete those files automatically on a specified time interval.
6. Inbuilt Export Data to Cloud Storage in Cloud Firestore
One of the places I worked at needed backups for their Firestore databases to keep their customer’s data secure in case of accidental deletion of their data by one of their employees or us. The thing I could never find is an “Export Data” button, even if it needs to export it to a cloud storage bucket, there should be an automated way to do so. There is a way to export and import data using Cloud Functions and another that uses Google Cloud’s services, but Firestore itself doesn’t have a scheduled backup solution and an import solution.
It will be very helpful for a lot of customers of Firestore, considering a few big businesses are starting to use Firestore for a few of their operations.
Other few features I would love Firebase to have that I won’t want to write paragraphs on are (I am going to keep adding more as I find more needs and hopefully some of them can become a reality):
- CDN in front of Firebase Cloud Storage.
- Firestore
getandexistsquery in Firebase Storage Security Rules, similar to the Firestore security rules. - Presence detection for Firestore (It’s actually happening as I write this! We will get our hands on it soon!).
- Detecting if a user is currently logged in on another device (Workarounds exist using Presence detection in Realtime Database and the soon upcoming Presence detection in Cloud Firestore).
- Always keep improving and don’t stop at this point, I am sure the Firebase team won’t stop improving their product.